Kelly Gambling
Introduction
In Kelly gambling (Kelly 1956), we are given the opportunity to bet on \(n\) possible outcomes, which yield a random non-negative return of \(r \in {\mathbf R}_+^n\). The return \(r\) takes on exactly \(K\) values \(r_1,\ldots,r_K\) with known probabilities \(\pi_1,\ldots,\pi_K\). This gamble is repeated over \(T\) periods. In a given period \(t\), let \(b_i \geq 0\) denote the fraction of our wealth bet on outcome \(i\). Assuming the \(n\)th outcome is equivalent to not wagering (it returns one with certainty), the fractions must satisfy \(\sum_{i=1}^n b_i = 1\). Thus, at the end of the period, our cumulative wealth is \(w_t = (r^Tb)w_{t-1}\). Our goal is to maximize the average growth rate with respect to \(b \in {\mathbf R}^n\):
\[ \begin{array}{ll} \underset{b}{\mbox{maximize}} & \sum_{j=1}^K \pi_j\log(r_j^Tb) \\ \mbox{subject to} & b \geq 0, \quad \sum_{i=1}^n b_i = 1. \end{array} \]
Example
We solve the Kelly gambling problem for \(K = 100\) and \(n = 20\). The
probabilities \(\pi_j \sim \mbox{Uniform}(0,1)\), and the potential
returns \(r_{ji} \sim \mbox{Uniform}(0.5,1.5)\) except for \(r_{jn} = 1\),
which represents the payoff from not wagering. With an initial wealth
of \(w_0 = 1\), we simulate the growth trajectory of our Kelly optimal
bets over \(P = 100\) periods, assuming returns are i.i.d. over time. In
the following code, rets is the \(K \times n\) matrix of possible
returns with rows \(r_j\), while ps is the vector of return
probabilities \((\pi_1,\ldots,\pi_K)\).
set.seed(1)
n <- 20 # Total bets
K <- 100 # Number of possible returns
PERIODS <- 100
TRIALS <- 5
## Generate return probabilities
ps <- runif(K)
ps <- ps/sum(ps)
## Generate matrix of possible returns
rets <- runif(K*(n-1), 0.5, 1.5)
shuff <- sample(1:length(rets), size = length(rets), replace = FALSE)
rets[shuff[1:30]] <- 0 # Set 30 returns to be relatively low
rets[shuff[31:60]] <- 5 # Set 30 returns to be relatively high
rets <- matrix(rets, nrow = K, ncol = n-1)
rets <- cbind(rets, rep(1, K)) # Last column represents not betting
## Solve for Kelly optimal bets
b <- Variable(n)
obj <- Maximize(t(ps) %*% log(rets %*% b))
constraints <- list(sum(b) == 1, b >= 0)
prob <- Problem(obj, constraints)
result <- solve(prob)
bets <- result$getValue(b)
## Naive betting scheme: bet in proportion to expected return
bets_cmp <- matrix(0, nrow = n)
bets_cmp[n] <- 0.15 # Hold 15% of wealth
rets_avg <- ps %*% rets
## tidx <- order(rets_avg[-n], decreasing = TRUE)[1:9]
tidx <- 1:(n-1)
fracs <- rets_avg[tidx]/sum(rets_avg[tidx])
bets_cmp[tidx] <- fracs*(1-bets_cmp[n])
## Calculate wealth over time
wealth <- matrix(0, nrow = PERIODS, ncol = TRIALS)
wealth_cmp <- matrix(0, nrow = PERIODS, ncol = TRIALS)
for(i in seq_len(TRIALS)) {
sidx <- sample(K, size = PERIODS, replace = TRUE, prob = ps)
winnings <- rets[sidx,] %*% bets
wealth[,i] <- cumprod(winnings)
winnings_cmp <- rets[sidx,] %*% bets_cmp
wealth_cmp[,i] <- cumprod(winnings_cmp)
}## Testthat Results: No output is goodGrowth curves for five independent trials are plotted in the figures below. Red lines represent the wealth each period from the Kelly bets, while cyan lines are the result of the naive bets. Clearly, Kelly optimal bets perform better, producing greater net wealth by the final period.
df <- data.frame(seq_len(PERIODS), wealth)
names(df) <- c("x", paste0("kelly", seq_len(TRIALS)))
plot.data1 <- gather(df, key = "trial", value = "wealth",
paste0("kelly", seq_len(TRIALS)),
factor_key = TRUE)
plot.data1$Strategy <- "Kelly Optimal Bets"
df <- data.frame(seq_len(PERIODS), wealth_cmp)
names(df) <- c("x", paste0("naive", seq_len(TRIALS)))
plot.data2 <- gather(df, key = "trial", value = "wealth",
paste0("naive", seq_len(TRIALS)),
factor_key = TRUE)
plot.data2$Strategy <- "Naive Bets"
plot.data <- rbind(plot.data1, plot.data2)
ggplot(data = plot.data) +
geom_line(mapping = aes(x = x, y = wealth, group = trial, color = Strategy)) +
scale_y_log10() +
labs(x = "Time", y = "Wealth") +
theme(legend.position = "top")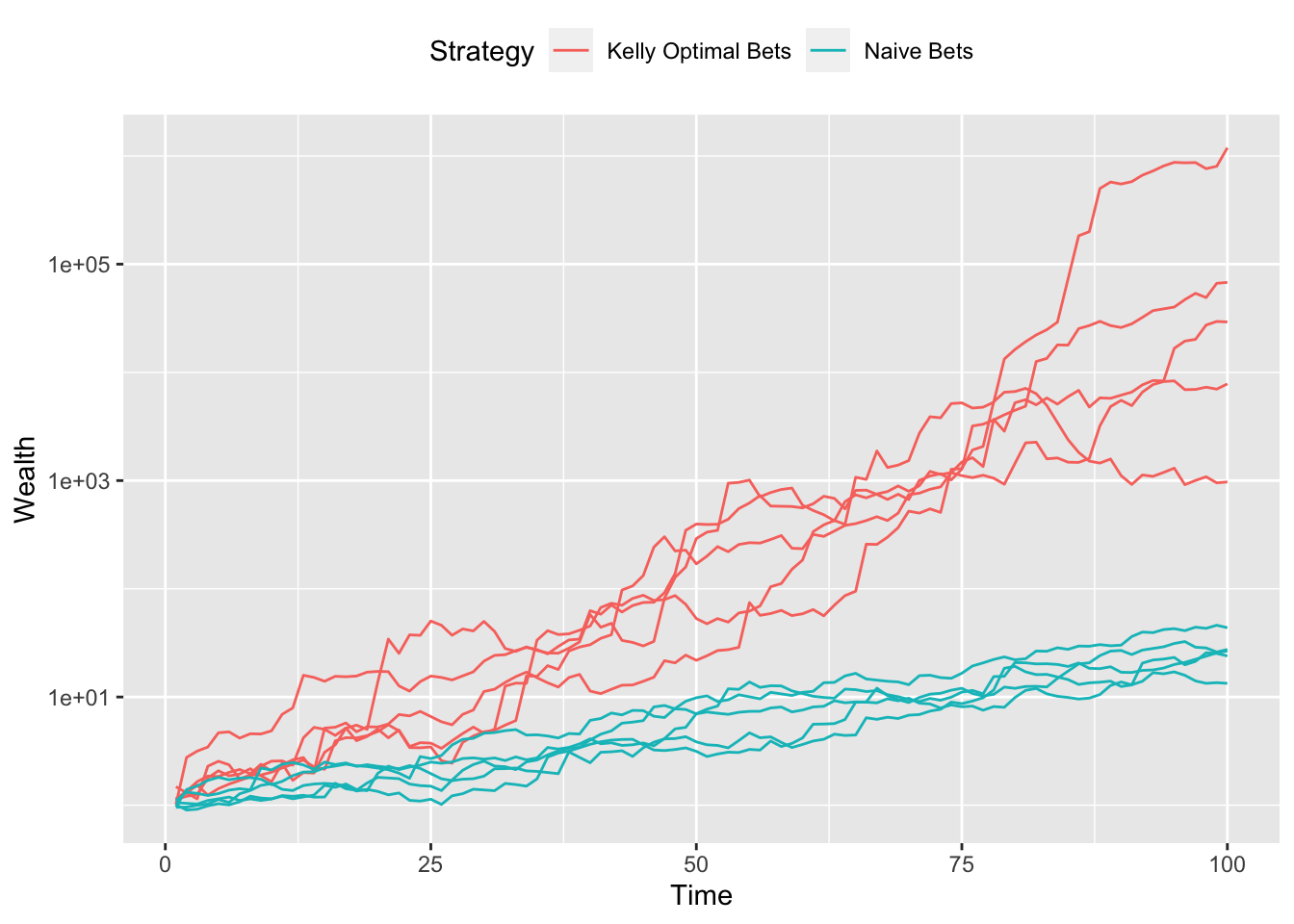
Extensions
As observed in some trajectories above, wealth tends to drop by a significant amount before increasing eventually. One way to reduce this drawdown risk is to add a convex constraint as described in Busseti, Ryu, and Boyd (2016, 5.3)
\[ \log\left(\sum_{j=1}^K \exp(\log\pi_j - \lambda \log(r_j^Tb))\right) \leq 0 \]
where \(\lambda \geq 0\) is the risk-aversion parameter. With CVXR,
this can be accomplished in a single line using the
log_sum_exp atom. Other extensions like wealth goals, betting
restrictions, and VaR/CVaR bounds are also readily incorporated.
Session Info
sessionInfo()## R version 4.4.1 (2024-06-14)
## Platform: x86_64-apple-darwin20
## Running under: macOS Sonoma 14.5
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.4-x86_64/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.4-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## time zone: America/Los_Angeles
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices datasets utils methods base
##
## other attached packages:
## [1] tidyr_1.3.1 ggplot2_3.5.1 CVXR_1.0-15 testthat_3.2.1.1
## [5] here_1.0.1
##
## loaded via a namespace (and not attached):
## [1] gmp_0.7-4 clarabel_0.9.0 sass_0.4.9 utf8_1.2.4
## [5] generics_0.1.3 slam_0.1-50 blogdown_1.19 lattice_0.22-6
## [9] digest_0.6.36 magrittr_2.0.3 evaluate_0.24.0 grid_4.4.1
## [13] bookdown_0.40 pkgload_1.4.0 fastmap_1.2.0 rprojroot_2.0.4
## [17] jsonlite_1.8.8 Matrix_1.7-0 ECOSolveR_0.5.5 brio_1.1.5
## [21] Rmosek_10.2.0 purrr_1.0.2 fansi_1.0.6 scales_1.3.0
## [25] codetools_0.2-20 jquerylib_0.1.4 cli_3.6.3 Rmpfr_0.9-5
## [29] rlang_1.1.4 Rglpk_0.6-5.1 bit64_4.0.5 munsell_0.5.1
## [33] withr_3.0.0 cachem_1.1.0 yaml_2.3.9 tools_4.4.1
## [37] Rcplex_0.3-6 rcbc_0.1.0.9001 dplyr_1.1.4 colorspace_2.1-0
## [41] gurobi_11.0-0 assertthat_0.2.1 vctrs_0.6.5 R6_2.5.1
## [45] lifecycle_1.0.4 bit_4.0.5 desc_1.4.3 cccp_0.3-1
## [49] pkgconfig_2.0.3 bslib_0.7.0 pillar_1.9.0 gtable_0.3.5
## [53] glue_1.7.0 Rcpp_1.0.12 highr_0.11 xfun_0.45
## [57] tibble_3.2.1 tidyselect_1.2.1 knitr_1.48 farver_2.1.2
## [61] htmltools_0.5.8.1 labeling_0.4.3 rmarkdown_2.27 compiler_4.4.1