loss_fn <- function(X, Y, beta) p_norm(X %*% beta - Y, 2)^2
regularizer <- function(beta) p_norm(beta, 2)^2
objective_fn <- function(X, Y, beta, lambd) {
loss_fn(X, Y, beta) + lambd * regularizer(beta)
}
mse <- function(X, Y, beta) {
(1.0 / nrow(X)) * value(loss_fn(X, Y, beta))
}Ridge Regression
Introduction
Ridge regression is a regression technique that is quite similar to unadorned least squares linear regression: simply adding an \(\ell_2\) penalty on the parameters \(\beta\) to the objective function for linear regression yields the objective function for ridge regression.
Our goal is to find an assignment to \(\beta\) that minimizes the function
\[ f(\beta) = \|X\beta - Y\|_2^2 + \lambda \|\beta\|_2^2, \]
where \(\lambda\) is a hyperparameter and, as usual, \(X\) is the training data and \(Y\) the observations. In practice, we tune \(\lambda\) until we find a model that generalizes well to the test data.
Ridge regression is an example of a shrinkage method: compared to least squares, it shrinks the parameter estimates in the hopes of reducing variance, improving prediction accuracy, and aiding interpretation.
In this example, we show how to fit a ridge regression model using CVXR, how to evaluate the model, and how to tune the hyperparameter \(\lambda\).
Writing the Objective Function
We can decompose the objective function as the sum of a least squares loss function and an \(\ell_2\) regularizer.
Generating Data
Because ridge regression encourages the parameter estimates to be small, it tends to lead to models with less variance than those fit with vanilla linear regression. We generate a small dataset that will illustrate this.
set.seed(1)
m <- 100
n <- 20
sigma <- 5
## Generate true coefficients
beta_star <- rnorm(n)
## Generate an ill-conditioned data matrix
X <- matrix(rnorm(m * n), nrow = m, ncol = n)
## Corrupt the observations with additive Gaussian noise
Y <- X %*% beta_star + rnorm(m, sd = sigma)
## Split into train and test sets
X_train <- X[1:50, ]
Y_train <- Y[1:50]
X_test <- X[51:100, ]
Y_test <- Y[51:100]Fitting the Model
All we need to do to fit the model is create a CVXR problem where the objective is to minimize the objective function defined above. We solve this for many values of \(\lambda\) to obtain the regularization path.
beta <- Variable(n)
lambd_values <- 10^seq(-2, 2, length.out = 50)
train_errors <- numeric(length(lambd_values))
test_errors <- numeric(length(lambd_values))
beta_values <- vector("list", length(lambd_values))
for (i in seq_along(lambd_values)) {
problem <- Problem(Minimize(objective_fn(X_train, Y_train, beta,
lambd_values[i])))
result <- psolve(problem, solver = "CLARABEL")
check_solver_status(problem)
train_errors[i] <- mse(X_train, Y_train, beta)
test_errors[i] <- mse(X_test, Y_test, beta)
beta_values[[i]] <- value(beta)
}Warning: Solution may be inaccurate. Try another solver, adjusting the solver settings,
or solve with `verbose = TRUE` for more information.
Solution may be inaccurate. Try another solver, adjusting the solver settings,
or solve with `verbose = TRUE` for more information.
Solution may be inaccurate. Try another solver, adjusting the solver settings,
or solve with `verbose = TRUE` for more information.Evaluating the Model
Notice that, up to a point, penalizing the size of the parameters reduces test error at the cost of increasing the training error, trading off higher bias for lower variance; in other words, this indicates that, for our example, a properly tuned ridge regression generalizes better than a least squares linear regression.
df_error <- data.frame(lambda = lambd_values,
Train = train_errors,
Test = test_errors) |>
pivot_longer(-lambda, names_to = "Set", values_to = "MSE")
ggplot(df_error, aes(x = lambda, y = MSE, color = Set)) +
geom_line() +
scale_x_log10() +
scale_color_manual(values = c(Train = "blue", Test = "red")) +
labs(x = expression(lambda), y = "Mean Squared Error (MSE)",
title = "Mean Squared Error (MSE)") +
theme_minimal()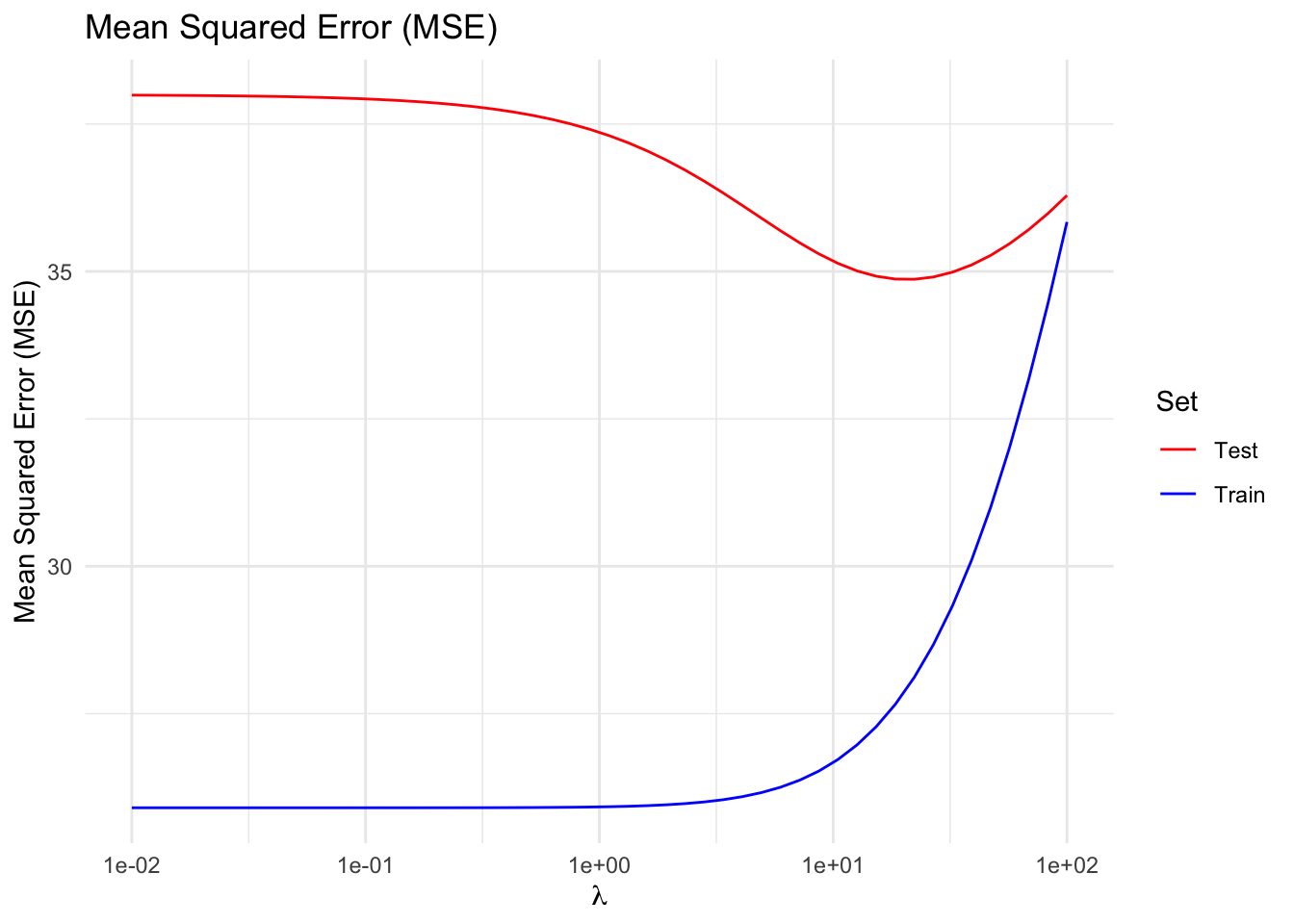
Regularization Path
As expected, increasing \(\lambda\) drives the parameters towards \(0\). In a real-world example, those parameters that approach zero slower than others might correspond to the more informative features. It is in this sense that ridge regression can be considered model selection.
beta_mat <- do.call(cbind, beta_values)
df_path <- data.frame(lambda = lambd_values, t(beta_mat)) |>
pivot_longer(-lambda, names_to = "Coefficient", values_to = "Value")
ggplot(df_path, aes(x = lambda, y = Value, color = Coefficient)) +
geom_line() +
scale_x_log10() +
labs(x = expression(lambda), y = expression(beta[i]),
title = "Regularization Path") +
theme_minimal() +
guides(color = "none")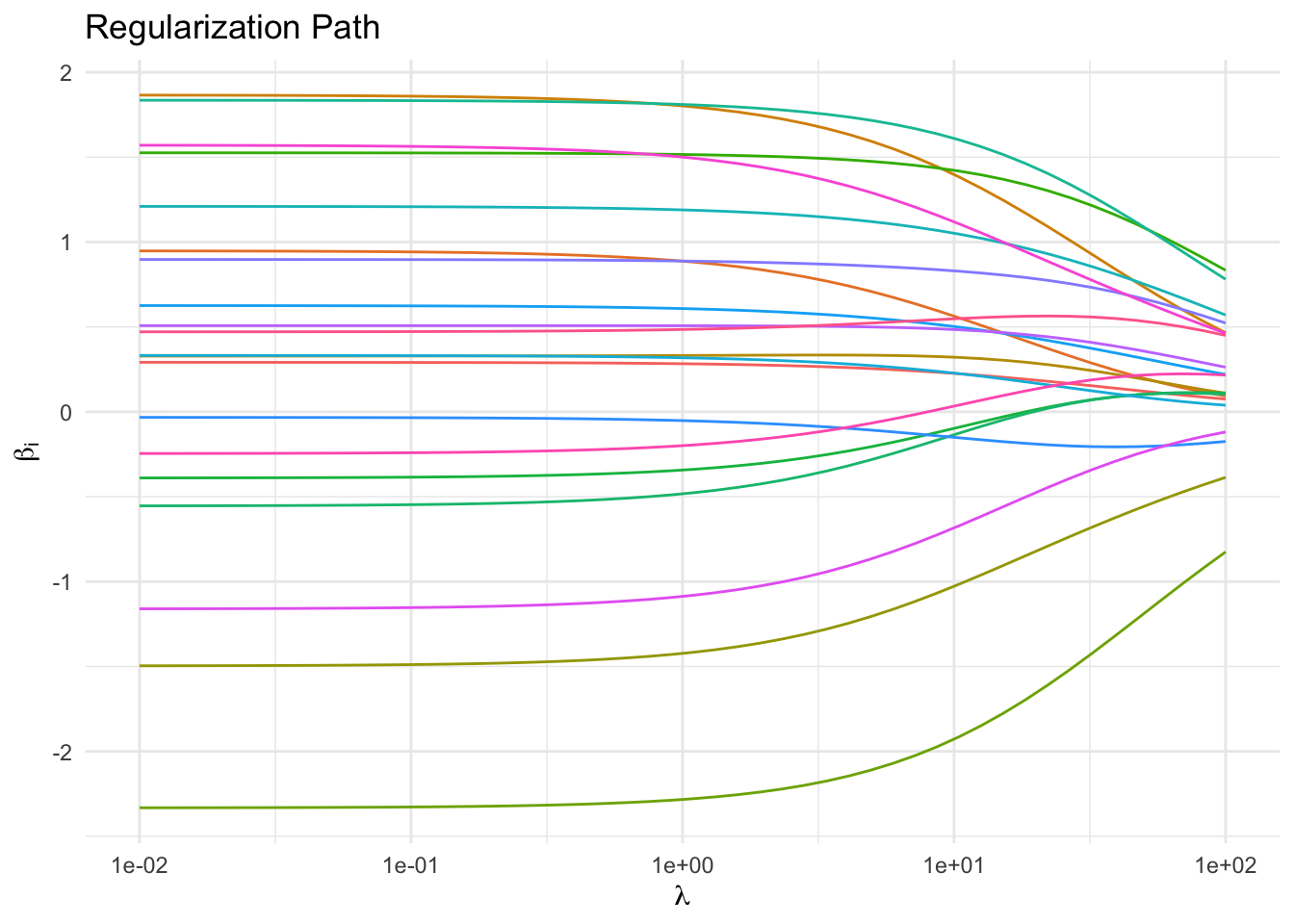
Session Info
R version 4.6.0 (2026-04-24)
Platform: aarch64-apple-darwin23
Running under: macOS Tahoe 26.5.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.6/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: America/Los_Angeles
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] tidyr_1.3.2 ggplot2_4.0.3 CVXR_1.9.1
loaded via a namespace (and not attached):
[1] Matrix_1.7-5 gtable_0.3.6 jsonlite_2.0.0 dplyr_1.2.1
[5] compiler_4.6.0 highs_1.14.0-2 tidyselect_1.2.1 Rcpp_1.1.1-1.1
[9] dichromat_2.0-0.1 scales_1.4.0 yaml_2.3.12 fastmap_1.2.0
[13] clarabel_0.11.2 here_1.0.2 lattice_0.22-9 R6_2.6.1
[17] labeling_0.4.3 generics_0.1.4 knitr_1.51 htmlwidgets_1.6.4
[21] backports_1.5.1 checkmate_2.3.4 tibble_3.3.1 rprojroot_2.1.1
[25] osqp_1.0.0 pillar_1.11.1 RColorBrewer_1.1-3 rlang_1.2.0
[29] xfun_0.58 S7_0.2.2 otel_0.2.0 cli_3.6.6
[33] withr_3.0.2 magrittr_2.0.5 digest_0.6.39 grid_4.6.0
[37] gmp_0.7-5.1 lifecycle_1.0.5 scs_3.2.7 vctrs_0.7.3
[41] evaluate_1.0.5 glue_1.8.1 farver_2.1.2 purrr_1.2.2
[45] rmarkdown_2.31 pkgconfig_2.0.3 tools_4.6.0 htmltools_0.5.9